Ant Group Unveils Ling-2.6-Flash: A Major Leap in AI Efficiency
Ant Group

Ant Group today officially announced the release of Ling-2.6-flash, a new large language model designed to prioritize efficiency and real-world application. Leveraging a sparse Mixture-of-Experts (MoE) architecture, the model utilizes 104 billion total parameters with only 7.4 billion active, delivering high intelligence at a fraction of the cost and latency of its peers.
This press release features multimedia. View the full release here: https://www.businesswire.com/news/home/20260422256825/en/
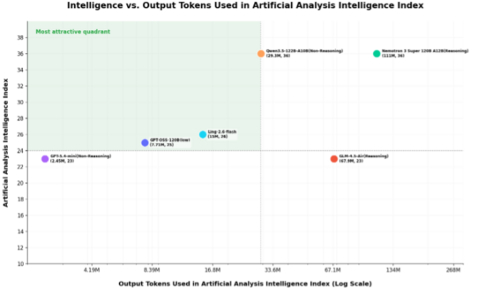
Unlike many models that rely on generating excessive tokens to achieve higher benchmark scores, Ling-2.6-flash focuses on token efficiency.
According to data from Artificial Analysis, Ling-2.6-flash demonstrates a significant advantage in efficiency. It achieved an Intelligence Index of 26 while generating only 15 million output tokens. Unlike some models that rely on excessively long outputs to achieve higher scores, Ling-2.6-flash strikes an optimal balance between intelligent performance and output cost.
In the complete Artificial Analysis Intelligence Index evaluation, Ling-2.6-flash consumed a total of 15 million tokens to complete tasks, whereas comparable models like Nemotron-3-Super consumed over 110 million tokens. For developers and enterprises, this equals an 86% reduction in inference cost, faster response times and a smoother user experience.
Built on a hybrid linear Mixture-of-Experts (MoE) architecture, the model delivers significant speed advantages. Under 4-card H20 conditions, it achieves inference speeds of up to 340 tokens per second, with a Prefill throughput 2.2 times that of Nemotron-3-Super. In Output Speed evaluations, Ling-2.6-flash ranks in the top tier of its size class with a stable output speed of 215 tokens per second.
Ling-2.6-flash has been specifically enhanced for AI agent applications, demonstrating state-of-the-art (SOTA) performance for its size on benchmarks such as BFCL-V4, TAU2-bench, SWE-bench Verified, Claw-Eval, and PinchBench. It maintains strong capabilities in general knowledge, mathematical reasoning, and long-text analysis while strictly controlling token consumption.
The official launch confirms that Ling-2.6-flash is the previously anonymous "Elephant Alpha." Prior to this release, the model was available for testing on OpenRouter under that codename, where it saw a significant surge in adoption. Over the past week, it topped the "Trending" charts for consecutive days, with daily token calls reaching the 100 billion level.
With pricing set at 0.1 USD for input and 0.3 USD for output per million tokens, the Ling-2.6-flash API is officially open. It includes a one-week free trial and is accessible through OpenRouter and the Alipay Tbox. A commercial version, LingDT, will be available through Ant Digital Technologies to support global developers and SMEs.
About Ant Group
Ant Group is a global digital technology provider and the operator of Alipay, a leading internet services platform in China, connecting over one billion users to more than 10,000 types of consumer services from partners. Through innovative products and solutions powered by AI, blockchain and other technologies, Ant Group supports partners across industries to thrive through digital transformation in an ecosystem for inclusive and sustainable development. For more information, visit www.antgroup.com.
View source version on businesswire.com: https://www.businesswire.com/news/home/20260422256825/en/
Contact details:
Media Inquires
Vick Li Wei
Ant Group
[email protected]

